国会の情報を整理するアプリを開発している話
ここ数ヶ月間、CapitaLens という国会の情報を整理するオープンソースのウェブアプリケーションを開発しています。CapitaLens は国会の情報を整理し、AI や自然言語処理で情報のアクセシビリティや透明性を向上し、誰でも簡単にアクセスできるようにするためのウェブアプリケーションです。
開発のきっかけ
このプロジェクトを始めたきっかけは、インターネット上の政治情報サイトを見て感じた問題感です。これらのサイトは人間の手で運用されているため、情報が偏ったり、地方自治体や行政レベルで情報が分散したりしています。
また、サイトのアクセシビリティもあまりいいものとは思えませんでした。
私はこの問題を解決するために、AI を活用して情報の整理とアクセシビリティの向上を図ることを思い立ちました。
大規模言語モデル
ChatGPT の登場で、大きな可能性を感じました。LLM は、行政や自治体などが公開しているデータを自然な言葉で分析する力を持っています。さらに、子ども向けに分かりやすく文章を要約するなど、情報のアクセシビリティが向上します。
最初は LangChain で様々なツールやエージェントを試していましたが、思い通り動いてくれなかったり SQL 生成などの際に問題となるプロンプトインジェクションなどかなり課題がありました。
そんな中、OpenAI から Function calling の API が公開されました。これにより、自然言語から、自分で定義した関数を自動的に呼び出し、任意のタスクを実行できるようになってしまいました。
これにより、SQL インジェクションなどの問題をほとんど起こさず、データ分析や家電操作などの可能性が広がりました。
試しにプロトタイプを開発してみたら、割と好評でびっくりました。JX 通信社の方からも見てもらえたみたいです。
メディアの進化
これまでメディアはテレビや新聞といった一方通行の形式が主流でした。しかし、次第に SNS や YouTube などプラットフォームで対話が可能になり、現在では読者からの質問や要望に基づいて LLM を使ってコンテンツを自動的に切り替えることが可能になってきました。
CapitaLens でも、この新たなメディアの形態を取り入れていることを目指し、マイルストーンの 1 つとして、無人の AI メディアの開発を目指しています。
具体的には、YouTube のライブストリームを利用して、最新の国会のニュースを自動生成し、ライブチャットからの反応に基づいてコンテンツを切り替えるなどの新しい体験を提供することを目指しています。
まとめ
また、最近では PolityLink さんのように、Whisper や NLP など、AI × シビックテックの組み合わせが増えてきており、その流れを加速させる一環として CapitaLens を開発しています。
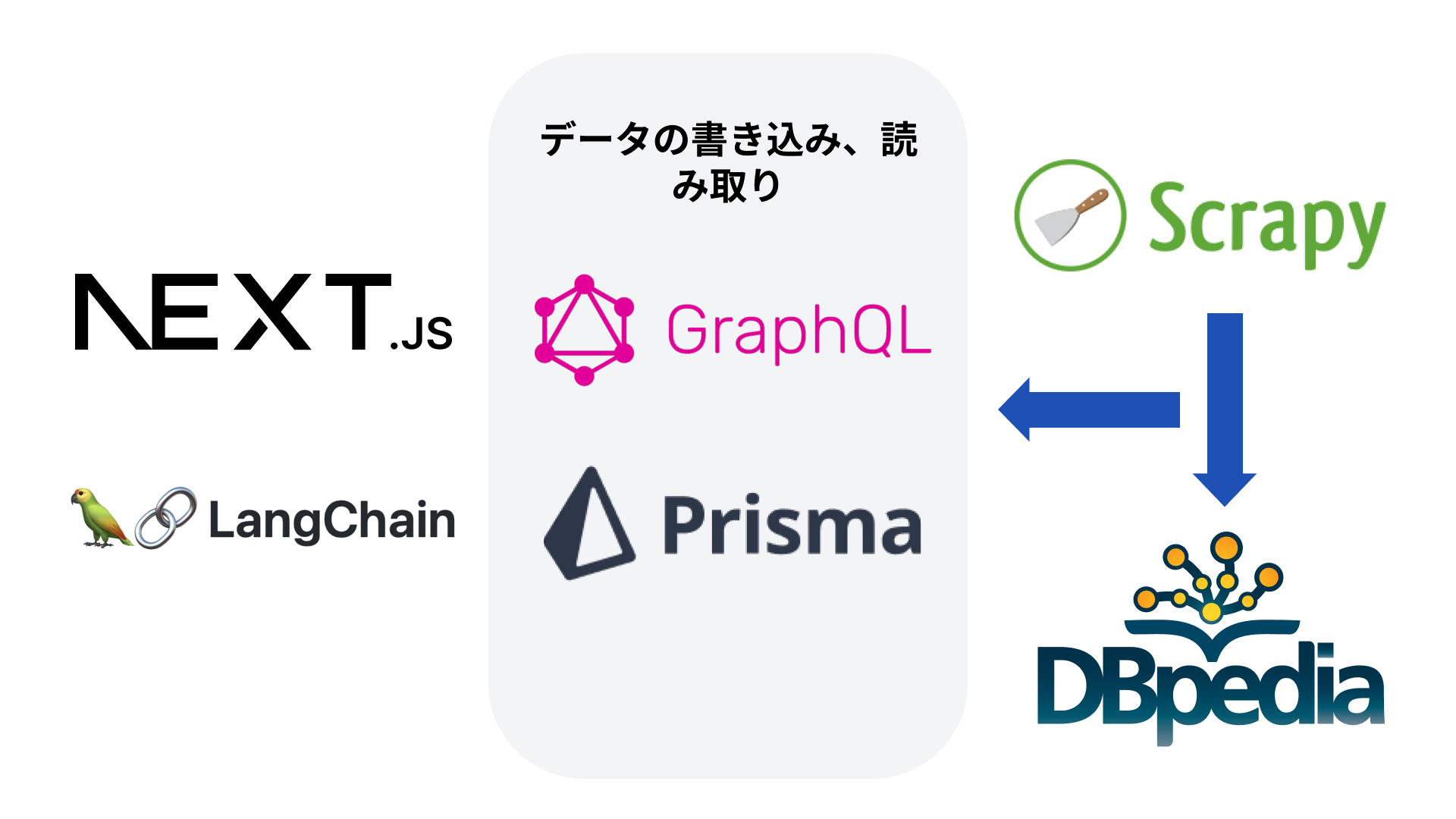
GitHub でソースコードも公開しているので、お気軽にフィードバックやコントリビュートをしていただけると嬉しいです!
このウェブサイト上のコンテンツは CC BY 4.0 DEED で利用できます